视频播放器原理
视频播放器拓扑结构
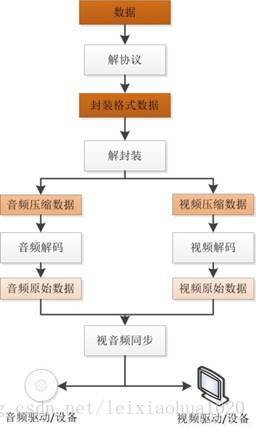
1 | 解协议的作用,就是将流媒体协议的数据,解析为标准的相应的封装格式数据。视音频在网络上传播的时候,常常采用各种流媒体协议,例如HTTP,RTMP,或是MMS等等。这些协议在传输视音频数据的同时,也会传输一些信令数据。这些信令数据包括对播放的控制(播放,暂停,停止),或者对网络状态的描述等。解协议的过程中会去除掉信令数据而只保留视音频数据。例如,采用RTMP协议传输的数据,经过解协议操作后,输出FLV格式的数据。 |
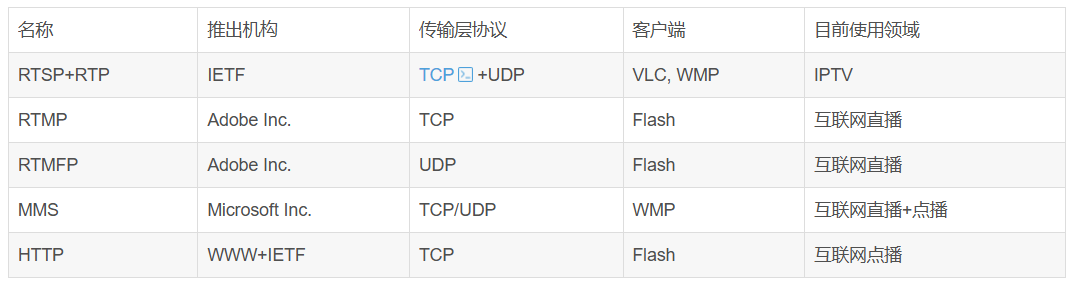
流媒体协议
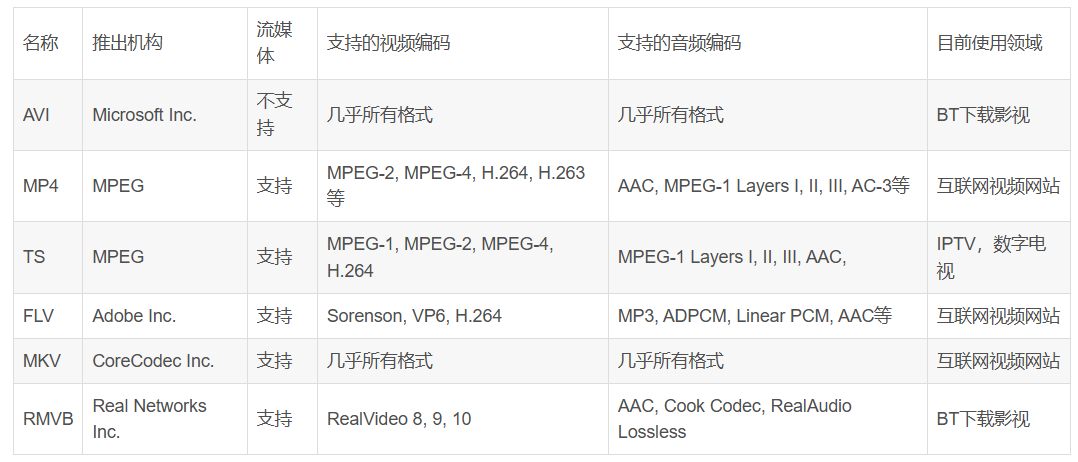
封装格式
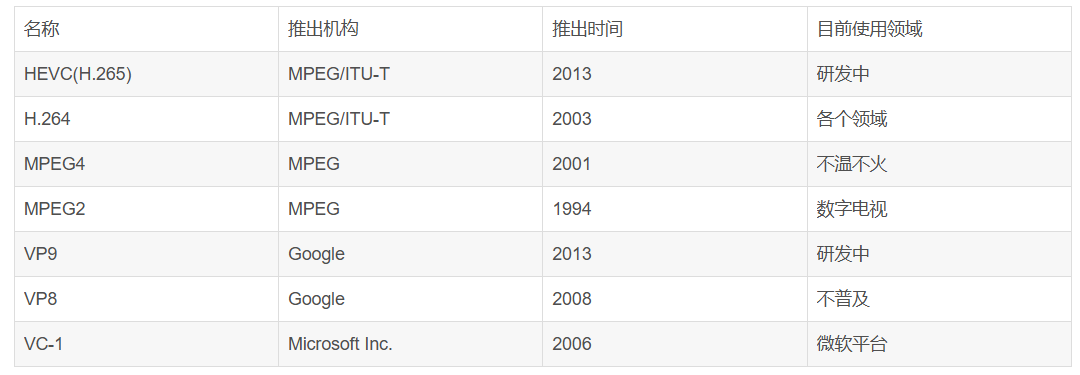
视频编码
音频编码
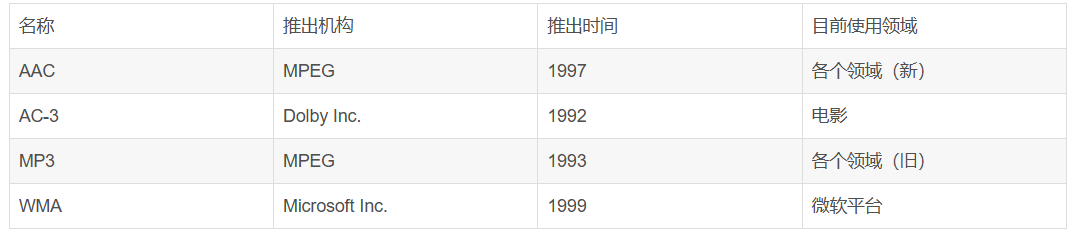
| 名称 | 推出机构 | 推出时间 | 目前使用领域 |
|---|---|---|---|
| LDAC | Sony Corporation | 2015 | 高分辨率无线音频传输,主要应用于索尼耳机/播放器与安卓设备之间(需要设备支持) |
关于LDAC的补充说明:
- 高分辨率音频传输: LDAC是索尼开发的一种音频编码技术,旨在通过蓝牙连接传输高分辨率(Hi-Res Audio)音频。它能够传输比传统蓝牙编解码器(如SBC)更高码率的数据,从而在无线传输中保留更多的音频细节。
- 码率: LDAC支持多种传输码率,最高可达990 kbps(在最佳连接条件下),这远高于SBC(最高约328 kbps)和aptX HD(576 kbps)。
- 应用场景: 主要用于索尼自家的音频产品(如WH-1000XM系列耳机、Walkman播放器)以及支持LDAC的安卓智能手机。它是安卓8.0(Oreo)及更高版本系统中的一个标准蓝牙音频编解码器。
- 局限性: 尽管LDAC能够传输高码率音频,但其传输质量受限于蓝牙连接的稳定性。在复杂的无线环境下,码率可能会自适应下降以维持连接。此外,其使用范围主要集中在索尼和安卓生态系统内,苹果iOS设备目前不支持LDAC。
- 与传统编码器的区别: 与你表格中列出的AAC、MP3、AC-3、WMA等主要用于音频文件存储和流媒体分发的编码器不同,LDAC更侧重于无线传输过程中的高质量编码,尤其是在蓝牙这个带宽有限的载体上。AAC、MP3等通常是音频文件的格式,而LDAC是传输协议的一部分,用于将这些格式的音频数据通过蓝牙高效传输。
上面介绍了常见的协议、封装、编码。下面举其中经典的例子来做原理说明
协议之RTSP
封装之FLV
flv封装由文件头和文件体组成,其中body部分由多个previous tag size四个字节,要来标志前一个tag的字节数据长度,第一个PTS为0 + tag有三种类型,包括音频、视频、和脚本类型.其中同样包括header和data。header一般为11字节组成。 具体如下:
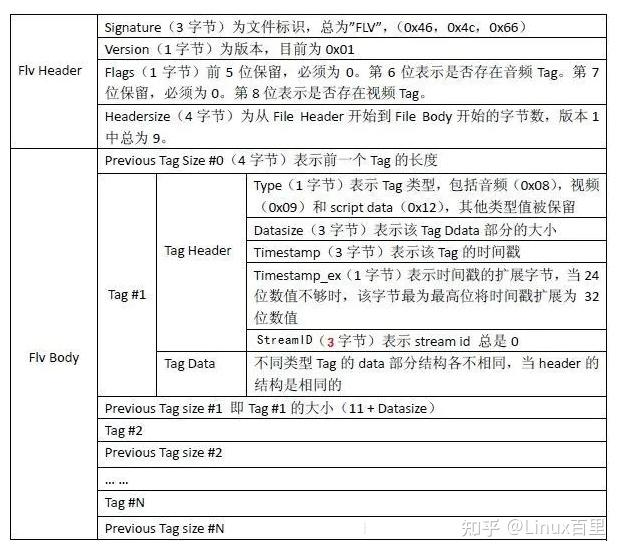
UI表示无符号整形,后面跟的数字表示其长度是多少位。比如UI8,表示无法整形,长度一个字节。UI24是三个字节,UI[8*n]表示多个字节。UB表示位域,UB5表示一个字节的5位。可以参考c中的位域结构体。
tag部分详解
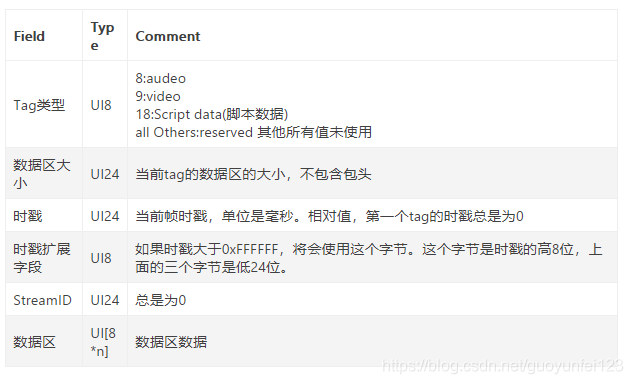
脚本类型tag
这里会存放一些相关与FLV视频和音频的元信息。比如:duration,width,heigth 等。通常该类型Tag会作为FLV文件的第一个tag,并且只有一个,跟在File Header后。该类型Tag DaTa的结构如下所示:
第一个AMF包:
第1个字节表示AMF包类型,一般总是0x02,表示字符串。第2-3个字节为UI16类型值,标识字符串的长度,一般总是0x000A(“onMetaData”长度)。后面字节为具体的字符串,一般总为“onMetaData”(6F,6E,4D,65,74,61,44,61,74,61)。
第二个AMF包:
第1个字节表示AMF包类型,一般总是0x08,表示数组。第2-5个字节为UI32类型值,表示数组元素的个数。后面即为各数组元素的封装,数组元素为元素名称和值组成的对。常见的数组元素如下表所示。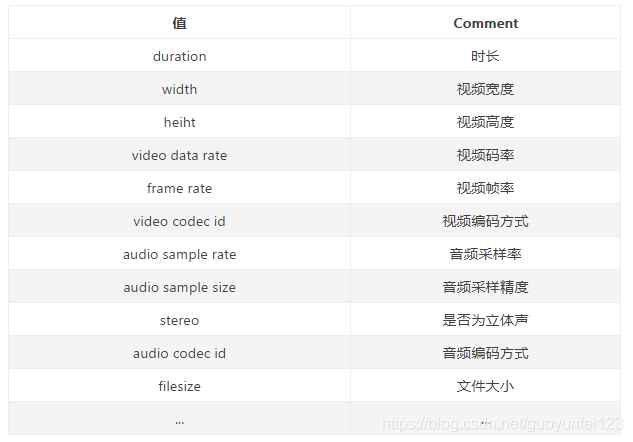
音频类型tag

第一个字节是音频信息,
第二个字节之后是音频信息。
视频类型tag

第一个字节信息
第二个字节之后是视频流
视频编码之H264
视频帧内编码
视频编码词用压缩技术来减少码率,而压缩的理论依据主要来源于:
- 数据冗余,通过关联图像中的各像素,来实现无损压缩
- 视觉冗余,在人眼的可分辨范围外通过引入客观失真来实现有损压缩。
变换编码:首先将源图像切割,然后对切割后的小块进行DCT变换,这个小块叫做宏块,在对图像块经过DCT变换后的系数进行量化,在传送过程中只传递一部分数据。实现有损压缩。实现有损压缩。
视频帧间编码
采用运动估计和运动补偿的方法来实现,第一步还是实现图像分割,然后在前一图像或者后抑恶图像某个搜索窗口的范围内未每一一个图像块寻找最为相似的图像块,通过计算这两个图像块的变换关系得到运动矢量。将两个图像块相减得到残差图像。前一个过程叫做运动估计,后一个过程叫做运动补偿。
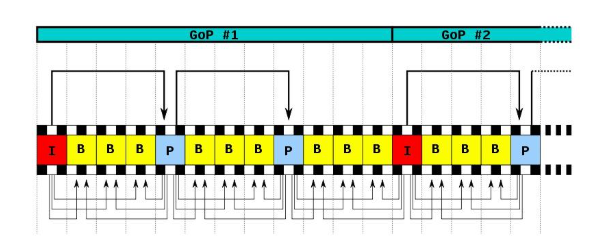
在H264中为了提高视频压缩质量,引入I帧、P帧、B帧。
I帧只使用本帧内数据编码,不需要考虑消除时间序列相关性。P帧使用前面的I帧或P帧来做运动估计和补偿。B帧使用前面的一个I帧或P帧,或后面一个I帧或P帧;来进行预测。使用B帧可以实现高压缩比。但是如果P帧和参考B帧遭到破坏,其他所有依赖于它们的帧就不能完整解码,这会直接导致视频故障。视频通常无法从此类问题中恢复。然而,当被破坏的视频流到达I帧,因为I帧被独立地编码解码,所以视频问题可以从I帧恢复。
一个序列的第一个图像叫做IDR 图像(立即刷新图像),IDR 图像都是 I 帧图像。引入 IDR 图像是为了解码的重同步,当解码器解码到 IDR 图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR图像之后的图像永远不会使用IDR之前的图像的数据来解码。
一个序列就是一段内容差异不太大的图像编码后生成的一串数据流。当运动变化比较少时,一个序列可以很长,因为运动变化少就代表图像画面的内容变动很小,所以就可以编一个I帧,然后一直P帧、B帧了。当运动变化多时,可能一个序列就比较短了,比如就包含一个I帧和3、4个P帧。
在视频编码序列中,GOP即Group of picture(图像组),指两个I帧之间的距离,Reference(参考周期)指两个P帧之间的距离。两个I帧之间形成一组图片,就是GOP。
编码器算法
视频编码器能够自主的比较帧内预测和帧间预测的结果,选择出最佳结果,即模式选择。并且编码器应该对每个宏块能做出如下处理:
- 后向预测(使用未来的帧)
- 前向预测(使用过去的帧)
- 无帧间预测,仅帧内预测
- 完全跳过(帧内或帧间预测)
下面重点解释一下B帧预测的逻辑。
我们用一个简化的模型来描述 B 帧的预测过程。假设我们有一个 GOP 结构,例如:I B B P B B I。
当编码器处理某个 B 帧时,例如,在 P1 和 P2 之间的 B1 帧:P1 ---> B1 <--- P2
B帧的预测通常涉及以下步骤:
确定参考帧列表 (Reference Picture Lists):
- 每个 B 帧在编码时会维护两个参考帧列表:
- List 0 (L0): 包含在其显示时间戳之前的参考帧(通常是 I 或 P 帧)。
- List 1 (L1): 包含在其显示时间戳之后的参考帧(通常是 I 或 P 帧)。
- 这些参考帧可以是比当前 B 帧更早或更晚解码的 I/P 帧。例如,对于
B1,P1位于 L0,P2位于 L1。
- 每个 B 帧在编码时会维护两个参考帧列表:
宏块或子块级别预测:
B帧的预测是以宏块(Macroblock,16x16 像素)或更小的子块为单位进行的。对于当前 B 帧中的一个宏块:a. 向前预测 (Forward Prediction):
- 编码器在 List 0 中的参考帧(例如
P1)中搜索与当前宏块最相似的区域。 - 找到最相似的区域后,计算出运动矢量 (Motion Vector, MV),这个 MV 指示了从参考帧中的哪个位置到当前宏块位置的位移。
- 记录下这个运动矢量和对应的预测残差(当前宏块与向前预测结果的差异)。
- 编码器在 List 0 中的参考帧(例如
b. 向后预测 (Backward Prediction):
- 编码器在 List 1 中的参考帧(例如
P2)中搜索与当前宏块最相似的区域。 - 计算出另一个运动矢量 (MV’)。
- 记录下这个运动矢量和对应的预测残差。
- 编码器在 List 1 中的参考帧(例如
c. 双向预测 (Bi-directional Prediction):
- 这是 B 帧特有的强大功能。编码器会尝试结合 向前预测的结果 和 向后预测的结果 来生成一个更准确的预测。
- 加权平均: 最常见的方法是对向前预测和向后预测的结果进行加权平均。例如,如果
B1刚好位于P1和P2的中间,可能会对两个预测结果各取 50% 进行叠加。 - 选择更好的预测模式: 编码器会比较三种预测模式(向前、向后、双向)产生的预测残差大小,选择残差最小的模式。残差越小,说明预测越准确,需要编码的数据量就越少。
编码残差和运动信息:
- 无论选择哪种预测模式,B 帧最终编码的都是预测残差(当前宏块的实际像素值与预测结果之间的差异)以及用于预测的运动矢量和参考帧索引。
- 由于预测残差通常包含的能量非常小(因为预测得很准确),所以经过变换、量化和熵编码后,数据量会非常小。
举例说明
假设我们有三帧画面,编码顺序和显示顺序可能如下:
- 显示顺序: F1 (I) -> F2 (B) -> F3 (P) -> F4 (B) -> F5 (P)
- 解码顺序(为了先解码参考帧): F1 (I) -> F3 (P) -> F2 (B) -> F5 (P) -> F4 (B)
我们聚焦在 F2 (B帧) 如何编码:
- 解码 F1 (I帧): F1 是一个完整的独立帧,不依赖其他帧。
- 解码 F3 (P帧): F3 依赖 F1 进行预测。编码器从 F1 中找到 F3 各个宏块的相似区域,记录下运动矢量和残差。
- 解码 F2 (B帧):
- F2 知道它在显示顺序上介于 F1 和 F3 之间。
- 对于 F2 中的一个宏块:
- 向前预测: 编码器在 F1 中找一个最像的块,记录 MV。
- 向后预测: 编码器在 F3 中找一个最像的块,记录 MV’。
- 双向预测: 将 F1 的预测块和 F3 的预测块进行平均或加权平均,形成一个双向预测块。
- 编码器会比较这三种方式的预测残差大小。例如,如果 F2 上的一个物体是从 F1 运动到 F3 过程中的中间位置,那么双向预测往往能得到最小的残差。如果 F2 上的一个静止背景在 F1 和 F3 中都有,那么向前或向后预测就足够了。
- 最终,F2 编码并存储:哪个预测模式、哪个参考帧(L0或L1)、运动矢量、以及实际的预测残差。
H264解析
同样的在H264中也有IBP帧类型,但是更重要的时其中的两层功能概念、NALU概念、slice、以及两种格式:
在H264中图像以序列为单位进行组织,一个序列是一段图像编码后的数据流。即NALU,它的功能分为两层,VCL(视频编码层)和NAL(网络提取层)。
两层功能
- VCL包括核心压缩引擎和块,宏块和片的语法级别定义,设计目标是尽可能独立于网路进行高效的编码。具体步骤如下:
- 压缩:预测(帧内预测和帧间预测)-> DCT 变化和量化 -> 比特流编码;
- 切分数据,主要为了第三步。这里一点,网上看到的“切片(slice)”、“宏块(macroblock)”是在VCL 中的概念,一方面提高编码效率和降低误码率、另一方面提高网络传输的灵活性。
- 压缩切分后的 VCL 数据会包装成为 NAL 中的一部分。
- NAL负责将VCL产生的比特字符串适配到各种各样的网络和多元环境中去。覆盖了所有片级以上语法。
NALU
NALU = header+Payload
header一般有一个字节组成,如下图
forbidden位在网络发生i错误的时候会被置为1,告诉对方丢掉这个单元。
nal_ref_idc表示当前NALU的重要性,若值小,在解码器处理不过来的时候可以选择丢掉
nal_unit_type表示NALU类型
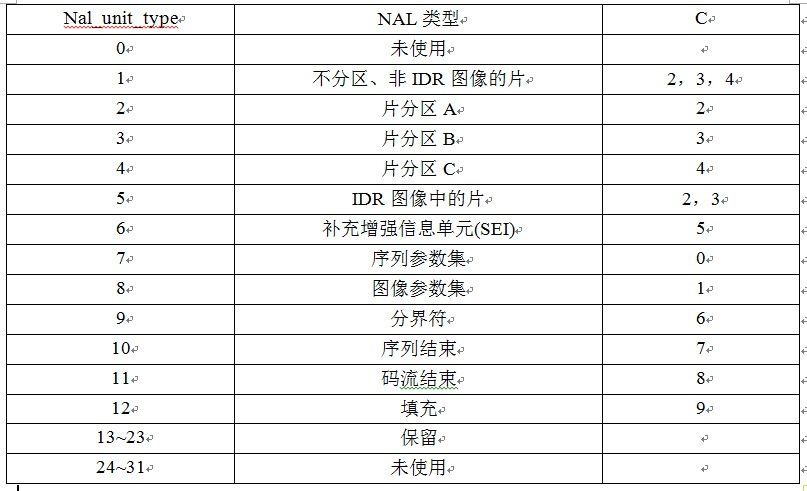
1-4:I/P/B帧,如果 nal_ref_idc 为 0,则表示 I 帧,不为 0 则为 P/B 帧。
5:IDR帧,I 帧的一种,告诉解码器,之前依赖的解码参数集合(接下来要出现的 SPS\PPS 等)可以被刷新了。
6:SEI,英文全称 Supplemental Enhancement Information,翻译为“补充增强信息”,提供了向视频码流中加入额外信息的方法。
7:SPS,全称 Sequence Paramater Set,翻译为“序列参数集”。SPS 中保存了一组编码视频序列(Coded Video Sequence)的全局参数。因此该类型保存的是和编码序列相关的参数。
8: PPS,全称 Picture Paramater Set,翻译为“图像参数集”。该类型保存了整体图像相关的参数。
9:AU 分隔符,AU 全称 Access Unit,它是一个或者多个 NALU 的集合,代表了一个完整的帧,有时候用于解码中的帧边界识别。
SPS 和 PPS 存储了编解码需要一些图像参数,SPS,PPS 需要在 I 帧前出现,不然解码器没法解码。而 SPS,PPS 出现的频率也跟不同应用场景有关,对于一个本地 h264 流,可能只要在第一个 I 帧前面出现一次就可以,但对于直播流,每个 I 帧前面都应该插入 sps 或 pps,因为直播时客户端进入的时间是不确定的。
对于Payload,H264也做了不同类型的规定- SODB,英文全称 String Of Data Bits,称原始数据比特流,就是最原始的编码/压缩得到的数据。
- RBSP英文全称 Raw Byte Sequence Payload,又称原始字节序列载荷。和 SODB 关系如下:RBSP = SODB + RBSP Trailing Bits(RBSP尾部补齐字节),引入 RBSP Trailing Bits 做 8 位字节补齐。
- EBSP英文全称 Encapsulated Byte Sequence Payload,称为扩展字节序列载荷。和 RBSP 关系如下:
EBSP :RBSP插入防竞争字节(0x03)
这里说明下防止竞争字节(0x03):可以先认为 H264 会插入一个叫做 StartCode 的字节串来分割 NALU,于是问题来了,如果 RBSP 中也包括了 StartCode(0x000001 或 0x00000001)怎么办呢?所以,就有了防止竞争字节(0x03):
slice
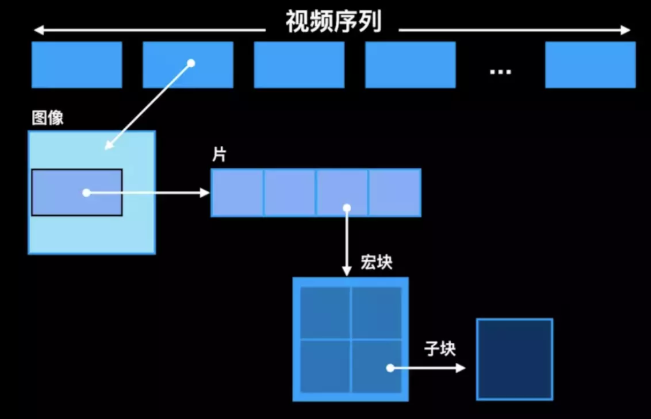
H264视频压缩后会成为一个序列帧,帧里包含图像,图像分为很多片,每个片可以分为宏块,每个宏块由许多子块组成 H264结构中,一个视频图像编码后的数据叫做一帧,一帧由一个片(slice)或多个片组成,一个片由一个或多个宏块(MB)组成,一个宏块由16x16的yuv数据组成。宏块作为H264编码的基本单位。
- 场和帧:视频的一场或者一帧可以用来产生一个编码图像。在电视中,每个电视帧都是通过扫描屏幕两次而产生的,第二个扫描的线条刚好填满第一次扫描所留下的缝隙。每个扫描即称为一个场。因此 30 帧/秒的电视画面实际上为 60 场/秒
- 片:每个图像中,若干个宏块被排列成片。片的目的:为了限制误码的扩散和传输,使编码片相互间保持独立。片共有5种类型:I片(只包含I宏块)、P片(P和I宏块)、B片(B和I宏块)、SP片(用于不同编码流之间的切换)和SI片(特殊类型的编码宏块)。NALU中承载的就是这些片
- 宏块:一个编码图像首先要划分成多个块(4x4 像素)才能进行处理,显然宏块应该是整数个块组成,通常宏块大小为16x16个像素。宏块分为I、P、B宏块,I宏块只能利用当前片中已解码的像素作为参考进行帧内预测;P宏块可以利用前面已解码的图像作为参考图像进行帧内预测;B宏块则是利用前后向的参考图形进行帧内预测
两种格式
分别为字节流AnnexB格式 和 AVCC格式。前者用于实时播放,后者用于存储
AnnexB格式
在这种格式中每个NALU都必须使用start code来分割(0x000001,单帧多个slice或0x00000001,帧之间,或者SPS、PPS等之前一般是四字节),并且SPS和PPS按流的方式写在头部。
NALU = header+EBSP
AVCC
在这种格式中,每一个NALU包都加上了一个指定其长度(NALU包大小)的前缀(in big endian format大端格式),这种格式的包非常容易解析,但是这种格式去掉了Annex B格式中的字节对齐特性,而且前缀可以是1、2或4字节,这让AVCC格式变得更复杂了,指定前缀字节数(1、2或4字节)的值保存在一个头部对象中(流开始的部分),这个头通常称为’extradata’或者’sequence header’。
音频编码之AAC
同样在音频方向也包括有损压缩和无损压缩。有损即去掉弱音信号或者去掉人耳听觉范围外的频率(<20Hz||>=20KHz)。关于采样率和采样位深等,一般音乐的采样频率时44.1khz,更高的可以是48khz,96khz。而语音通话或者识别的采样较低,一般分为宽带(50Hz–7000Hz,采样率16000Hz)和窄带(300Hz-3400Hz,采样率8000Hz),主流语音采样时16kHz。采样位深常用16位。
关于音频的采集和播放,一般使用专门的芯片(codec)来采集音频,做A/D转换,然后将数字信号通过I2S总线(或者PCM总线)来送到CPU进行处理(也有部分方案使用codec和CPU集成)。当播放音频时CPU将音频信号通过I2S总线送给codex芯片,然后D/A转换得到模拟信号播放。
关于音频的采样量化等方法以传统的PCM为例。值得一提的是目前PCM编码有三种标准,来自链接
ITU,主要制定有线语音的压缩标准(g系列),有g711/g722/g726/g729等。
3GPP,主要制定无线语音的压缩标准(amr系列等), 有amr-nb/amr-wb/EVS。后来ITU吸纳了amr-wb,形成了g722.2。
MPEG,主要制定音乐的压缩标准,有11172-3,13818-3/7,14496-3等。
一些大公司或者组织也制定压缩标准,比如iLBC,OPUS。
常见的无损方法:
- FLAC (Free Lossless Audio Codec): 目前最流行的无损音频编码格式,开源、免费。
- APE (Monkey’s Audio): 另一种流行的无损格式,但解码复杂度较高。
- ALAC (Apple Lossless Audio Codec): 苹果开发的无损格式,用于其生态系统。
- WavPack (WV): 灵活的混合模式无损格式。
- DSD/DSF/DFF: 用于高解析度音频的特殊无损格式,不完全是 PCM 编码。
有损方法较多,后面再详细学习,这里只聊一下AAC。
AAC编码文件格式文件有两种:
ADIF:Audio Data Interchange Format 音频数据交换格式。这种格式的特征是可以确定的找到这个音频数据的开始,不需进行在音频数据流中间开始的解码,即它的解码必须在明确定义的开始处进行。故这种格式常用在磁盘文件中。
ADTS:Audio Data Transport Stream 音频数据传输流。这种格式的特征是它是一个有同步字的比特流,解码可以在这个流中任何位置开始。它的特征类似于mp3数据流格式。这种格式可以用于广播电视。
简言之。ADIF只有一个文件头,ADTS每个包前面有一个文件头。
对于AAC的头,一般为七个字节或者五个字节。具体头格式查表。
硬件上的音频
andriod系统中的audio有三种播放模式,low latency playback、deep buffer playback和compressed offload playback
- low latency payback:用于低延迟,按键音等场景。AP->audioDSP->codec
- deep buffer playback:用于音乐等对时延要求不高的声音输出。音频文件是在AP侧解码成PCM数据,如果有音效的话会再对PCM数据处理(android audio framework中有effect音效模块,支持的音效有均衡器、低音增强、环绕声等),然后再经由Audio DSP送给codec芯片播放出来。
- compressed offload playback:用于音乐等声音输出,但是音频解码部分的工作是在Audio DSP中完成,AP侧只负责把音频码流送到Audo DSP中,送出去后AP侧会进行休眠,Audo DSP中会分配一块较大的buffer去处理此数据,在Audo DSP中进行解码、音效的处理等工作,在Audo DSP解码器处理完数据之前,它会唤醒AP侧去送下一包数据。用这种模式播放音频能有效的降低功耗,是最为推荐的播放音乐的模式。但是在目前的主流的音乐播放APP中用的基本上都是deep buffer的播放模式,比如QQ音乐、网易云音乐和酷狗音乐等。看来系统平台厂商和APP厂商的做法是有差异的。至于哪些格式的音乐用这种模式播放,这需要在audioPolicy中去控制,我做的平台上是MP3(.mp3)和AAC(.m4a)用offload模式播放,因为这两种格式最主流。
