音视频同步
请阅读文章,检查其中是否有疏漏
关于音视频同步,有很多工程实践上的具体问题,这篇文章并不打算总结过往开发中出现的所有问题,而是针对于一个视频会议场景,讨论其中的同步细节,因为他们的发生往往是由于多种因素,例如语音数据前处理的3A算法引入的几毫秒误差,视频前处理(例如美颜等)引入的几十毫秒误差,缓冲队列的深度不够无法补偿两者的误差,甚至于软解硬解方案不同导致的编解码速度误差都会因此音视频不同的情况发生。而这些情况往往通过抓包,分析帧数据,打日志等方案都能够找到蛛丝马迹,因此最重要的是核心的同步原理,对于不同的库,其提供的帮助同步方法的API是什么。
首先应该了解的是,音视频之间的延迟在什么范围内是可以接受的以及延迟是如何被计算的。
- **-180 <= Video_delay - audio_delay <=90 **,一般以此作为同步的最低标准。
- 假设音视频的采集和渲染延迟相等,考虑延迟为
1 | diff = 视频端到端延迟-音频端到端延迟 |
从以上可以轻松的看出,衡量其他步骤延迟,调节发送和接收两端的buffer深度,就能够解决同步问题。
那么如何衡量延迟大小,发送端可以通过设置时钟通过timebase等参数做粗略的对齐。接收端则复杂一些,通过解包需要知道以下信息:
- 视频,音频帧采集时间戳
- 音频帧接收时间,视频帧组帧结束时间
- JB延迟
在不同的协议中一般都会有DTS PTS或者其他类型timestamp。甚至还有NTP,例如webrtc中的SR报文,提供了非常精准的时间戳。而保证音视频同步,核心就是保证音视频的PTS差在范围内,尽管音视频单位时间的样本数不同,但是保证PTS就可以忽略这个细节。于是就有各种同步策略,可以是音频同步到视频(减速或加速音频JB),视频同步到音频(视频丢帧),两者收敛(webrtc使用),等等等等。
以视频会议为例
在视频会议场景中,简单来说音视频处理基本流程是这样的:
1 | 采集->解码->编码->封装->webRTC协议发送 |
在这个过程中,解决RTP和NTP时间的正交性是问题的关键。首先,问题出现的原因是为了防止预测攻击,RTP的其实时间戳必须是随机的,且后续单调递增,而且由于音频,视频都用有各自的起始偏移,仅凭RTP头是无法计算相对关系的,另外NTP仅取决于NTP服务器的时钟,这是一个64位定点数(32位秒 + 32位小数),也是连接音频和视频的唯一锚点。
为了讨论RTP中的时间戳,首先考虑链路中时间基转换的问题,时间基即采样率的倒数,可以理解为是独特的时间基准。同步中,需要在跨越不同模块时传递TimeStamp,在采集层,CLOCK_MONOTONIC单位可能是纳秒或者微秒。在ffmpeg层timebase音频可能是1/48000,视频可能是1/90000。在跨越不同模块的时候就要根据timebase进行av_rescale_q。
本地得到一个真实的同步的tImestamp之后,开始进行RTP的封包以及传输,在webrtc中(RTSP之类的协议同样)使用RTCP每隔一段时间会发送一个RTCP Sender Report包,来进行各种参数的协商,其中就包括RTP与NTP的映射关系,接收端利用 SR 建立线性映射关系。假设接收端在 $t_{arrival}$ 时刻收到一个视频 RTP 包,其时间戳为 $RTP_{frame}$。为了知道该帧对应的绝对采集时间 $T_{capture}$,接收端必须找到最近一次收到的视频 SR 包(包含 $SR_{RTP}$ 和 $SR_{NTP}$),并执行以下插值计算:
$$T_{capture_video} = SR_{NTP} + \frac{(RTP_{frame} - SR_{RTP})}{Frequency_{video}}$$
对于音频也是同样的,易得:
$$\Delta_{sync} = T_{capture_video} - T_{capture_audio}$$
对于SFU架构下的视频会议还需要引入绝对采集时间 (abs-capture-time),采集端在生成 RTP 包时,直接将 64 位的 NTP 采集时间戳写入 RTP 头部扩展中,来解决SFU 可能会重写 RTP 时间戳和 SSRC,从而破坏原有的 RTCP SR 映射关系。
另外RTP提供了一个video-timing扩展位,包含 Encode Start, Encode Finish, Packetization Complete, Pacer Exit字段,可以用来区分不同阶段产生的延迟。
接收端处理得到了音频和视频的绝对采集时间之后就可以开始进行同步操作了,音频一般使用NetEQ对帧进行处理,视频则是在VCM渲染队列完成,关于两者JB深度的计算,渲染、解码策略时间的计算都有记录。
对于每一帧的视频系统都会计算理论的渲染时间 $T_{render} = T_{capture} + \Delta_{target_delay}$。然后,查询当前音频的播放进度 $T_{audio_playout}$。
易得:
$$相对误差 E = T_{render} - T_{audio_playout}$$
接下来进行上面提到了同步策略,webrtc通过两者的收敛实现同步,具体未音频增加或者减少采样点,视频丢帧或立即渲染。
以上重点讨论了RTP传输过程中的同步问题,另外是,端侧实现,以ffmpeg为例来说明。在ffmpeg内部无论是视频还是音频的packet都有pts字段,核心的是进入编码器的每一帧->PTS必须是单调递增的。在视频采集过程中,由于不同的摄像头规格不同,可能会出现帧率的波动,这个时候应该进行补帧或者丢帧,主要的判断依据是Current_PTS - Last_PTS。而对于音频的采集过程要添加FIFO队列来满足音频编码器对采样点数的要求,例如AAC编码器要求1024个采样点,因此要在fifo队列中积攒出1024个采样点之后再发送帧,同时这个帧的PTS应该使用
$$PTS_{next} = PTS_{start} + \frac{TotalSamplesSent}{SampleRate}$$
来计算,注意这是基于采样点的计算。
另外就是H264的B帧问题,这可以通过设置ffmpeg的APihas_b_frames来实现,内部完成PTS、DTS编排。
时钟同步
而关于时钟同步,同样是一个场景工程实践问题,如何同步多端的NTP时钟毫无疑问是一个关键问题,前段时间在群里其实就看到有一些人在讨论如何做到多个麦克风同步播放音频(20ms内)。这里也是讨论同步策略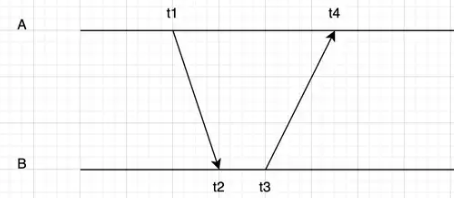
其中A是待同步,B是NTP服务器
$$ ntp_{offset} = NTP_b - NTP_a $$
容易得到
$$ t_1 + ntp_{offset}+ +rtt/2 = t_2 $$
$$ t_3 + rtt/2 = t_2 + ntp_{offset} $$
$$ ntp_{offset} = (t_2-t_1+t_3-t_4)/2+rtt/2$$
$$rtt = (t_4-t_1)-(t_3 - t_2)$$
但是这种过于简单的方法,一定是不鲁棒的,例如rtt变化等。在群里看到有人提到了DANTE传输技术,基于精准时钟恢复的PLL,这些或许都是更有效的方案,将来遇到这个场景再去探索一下。
webrtc的端到端延迟计算
如果我们采用了某种方案实现了NTP的同步,那么计算端到端延时就很容易了(采集->播放)。但是一般的webrtc场景肯定不会采用如此专业的ntp同步手段的。因此webrtc使用程序中打的时间戳来计算端到端延迟,可以看issue
具体步骤是,首先根据SR包中的时间戳回复成发送端NTP(最小二乘),估算上下行的RTT,WebRTC里面采用的是平滑中值滤波MovingMedianFilter来对ntp offset进行滤波,能够实现单向一次较为准确的估算RTT,最后 基于接收端的ntp时间,用帧的渲染时间 - 帧的采集时间。采集时间是经过上面的两步转换,即RtpToNtpEstimator和RemoteNtpTimeEstimator,将采集时间映射到接收端的时间。
但必须清楚的是真实世界一定是更为复杂的,例如晶振漂移。
